
1. 초기 우리의 서비스
해커톤 동안 MVP가 가장 우선순위에 있었기 때문에 서버분들이 API 명세서를 주는대로 바로 개발을 진행해야 했습니다.
useEffect(() => {
const getUserWatchDataApi = async () => {
...
};
getUserWatchDataApi();
}, []);그래서 처음엔 익숙했던 useEffect를 사용해서 비동기 통신을 처리하는 로직들을 작성하였습니다.
하지만 추후 리팩토링을 진행하면서 TanstackQuery와 Suspense를 도입하고 리액트의 주요 개념인 선언형 프로그래밍을 통하여 비동기 작업의 복잡성을 크게 줄여주고 코드의 가독성을 높이기 위해 노력하였습니다.
2. useSuspenseQuery와 Suspense 도입하면서
처음엔 하나의 API 호출을 통해서 영상에 대한 기본 정보, 유저 답변 정보, GPT 응답 정보등을 받아올 수 있는 형태였고 데이터를 받아서 props로 내려주거나 바로 렌더링을 진행하는 식으로 구성하였습니다.
<Suspense
fallback={Array.from({ length: 3 }, (_, idx) => (
<Skeleton key={idx} className="h-44" />
))}
>
<Information />
</Suspense>;
- Information 컴포넌트
export const Information = () => {
const { data } = useGetViewByVideo(params);
return (
...
);
};
2.1 OpenAI API 무료버전 사용 시 발생한 문제
서버에서 OpenAI API 무료 버전을 사용해서 응답을 받고 있었는데 트래픽이 몰리는 시간에 특히나 속도 저하가 심해져서 프론트에선 하염없이 응답을 기다릴 수 밖에 없는 문제가 발생하였습니다. 특히 사용자의 입장에선 Gpt의 느린 응답 속도 때문에 오랫동안 스켈레톤 UI만 바라보는 답답함을 느끼게 되었습니다.
해당 문제를 해결하기 위해선 저희에겐 2가지 정도가 선택지가 있었습니다.
- 유료버전 OpenAI API로 변경
- 기본 정보라도 유저에게 먼저 제공한 후 Gpt의 응답을 기다리는 방식으로 변경
유료버전을 사용하게 된다면 성능과 속도 면에서 저희 서비스에 더 적합했지만, 비용 문제가 걸림돌이 되었습니다.
결국, 현재 상태에서 최선의 선택인 2번 방안을 적용하여 서비스를 업데이트하기로 결정하였습니다.
회의를 통하여 기존처럼 GPT 응답, 영상에 대한 기본 정보, 유저의 답변을 한번에 받아오는 구조가 아닌, 각 데이터를 개별적으로 요청하는 API 구조로 변경하였습니다.
API 설계 변경에 따라 프론트엔드에서도 여러가지 사항을 고려해야 했습니다.
- Waterfall 현상을 방지하기 위해 병렬적으로 어떻게 API를 요청해야 되는가?
- Suspense와 API 요청을 어떻게 구성하면 유저에게 좋은 경험을 제공할 수 있을까?
- GPT의 응답이 오기 전까지 어떤 UI를 제공해야 사용자 경험이 좋을까?
이를 바탕으로 프론트엔드 구조를 수정하고, 유저에게 더 나은 경험을 제공할 수 있도록 개선 작업을 진행했습니다.
3. API마다 Suspense를 구성
처음에는 각 API마다 Suspense를 구성하는 방식을 고려했습니다. 이를 통해 개별 API 요청이 병렬적으로 처리되는 지 확인할 수 있었고, 각각의 컴포넌트에서 독립적으로 데이터를 가져오도록 만들 수 있었습니다.
하지만
1. GPT의 응답속도가 느리다고 각각 별도의 로딩처리가 과연 적절한가?
2. 오히려 유저가 예상하지 못한 방식으로 로딩 UI가 분리되는 건 아닌가? 하는 의문이 들기 시작했습니다.
실제로 적용된 화면을 보면서, 기존엔 하나의 Skeleton UI로 통합된 로딩화면을 제공했으나, API 별로 Suspense를 적용하면서 각각의 독립적인 로딩 상태가 나타나 UX가 오히려 더 복잡해졌다는 생각이 들었습니다.
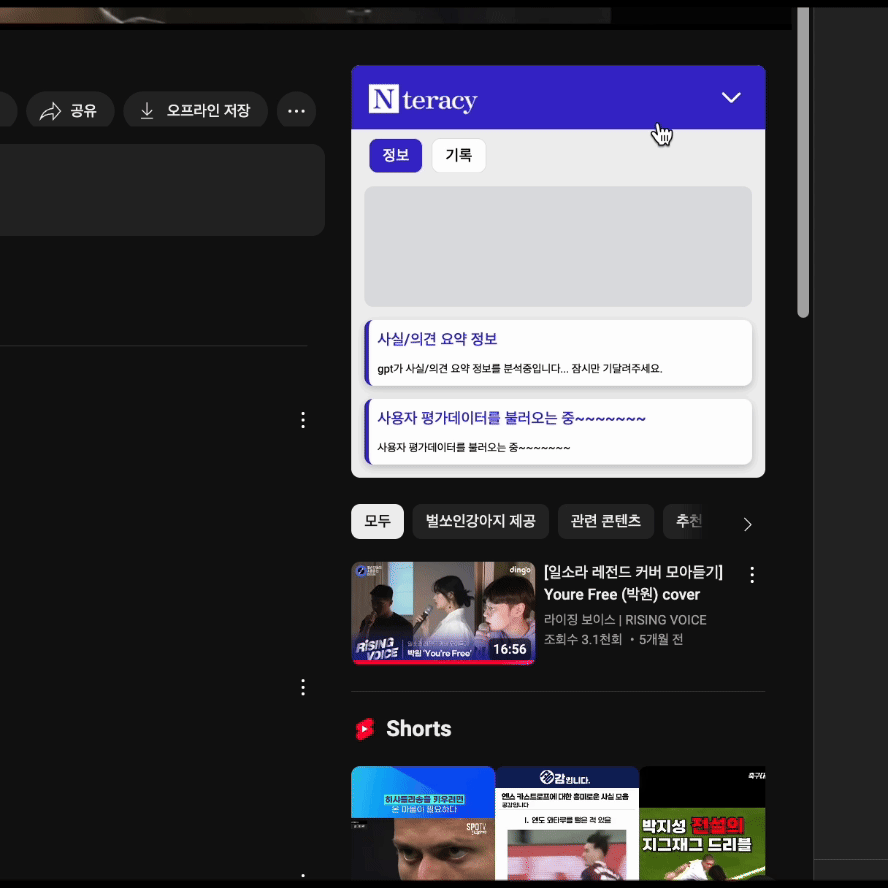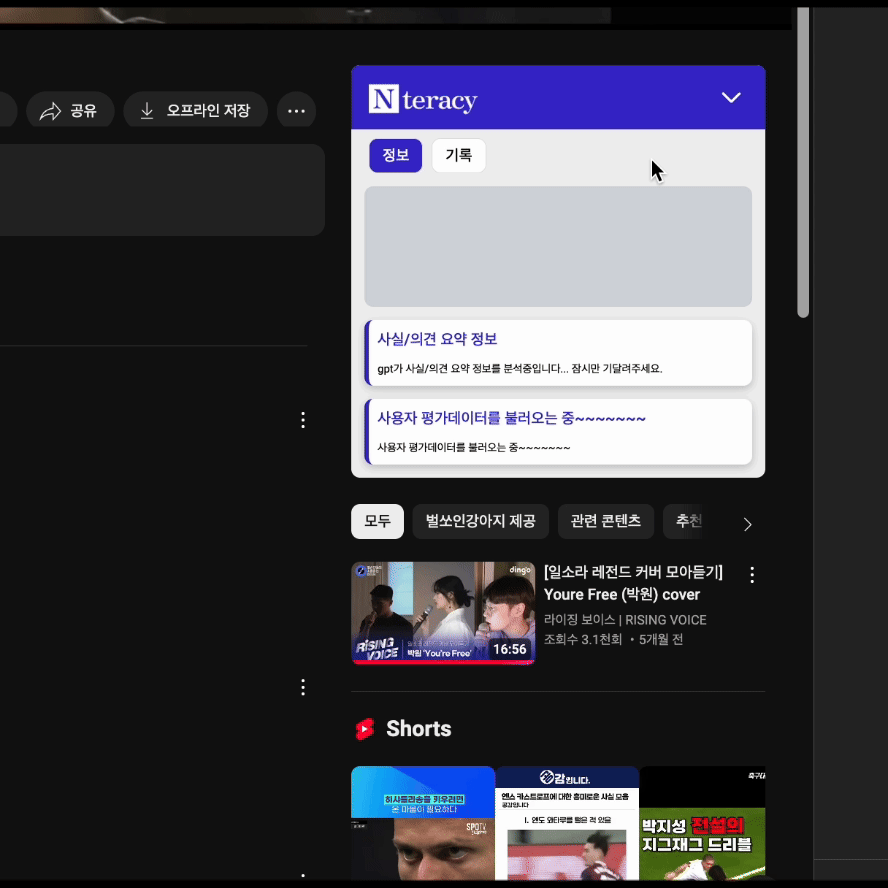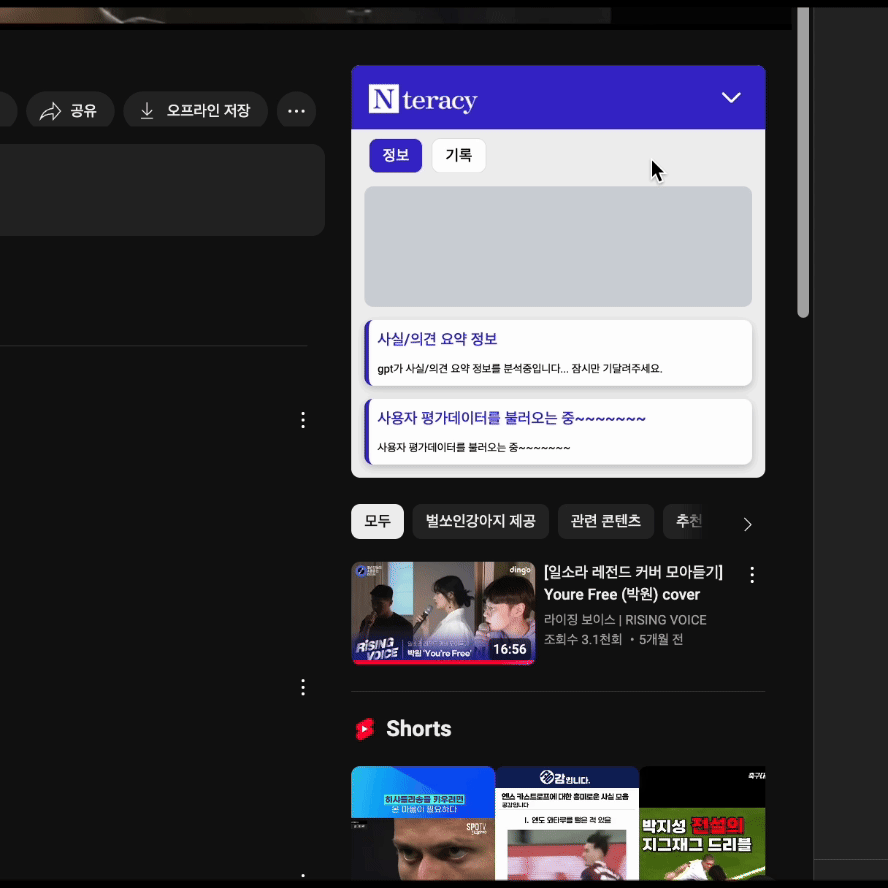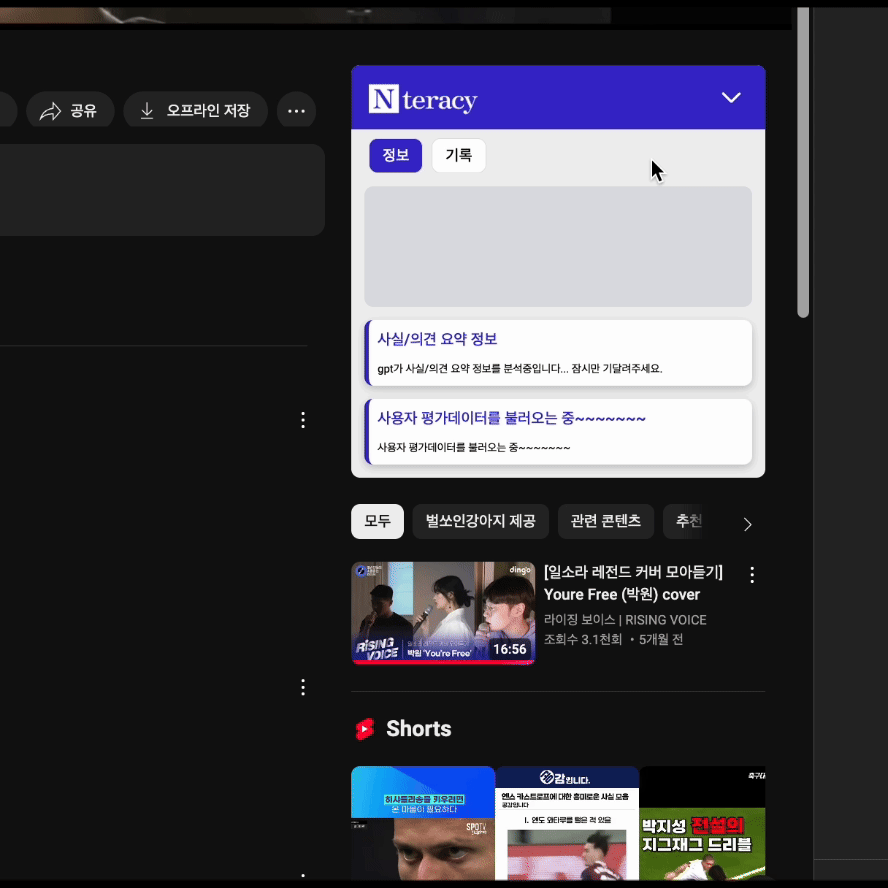
<Fragment>
<Suspense fallback={<Loading />}>
<YoutubeInfoContainer />
</Suspense>
<Suspense fallback={<Loading />}>
<GptAnswerContainer />
</Suspense>
<Suspense fallback={<Loading />}>
<Card title="사용자 평가">
<NewsEvaluationForm />
</Card>
</Suspense>
</Fragment>;
4. 하나의 Suspense와 두개의 API 요청과 중첩 Suspense 적용
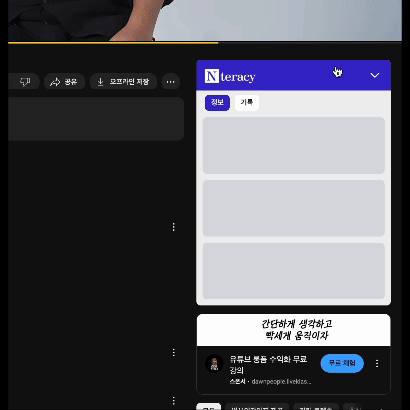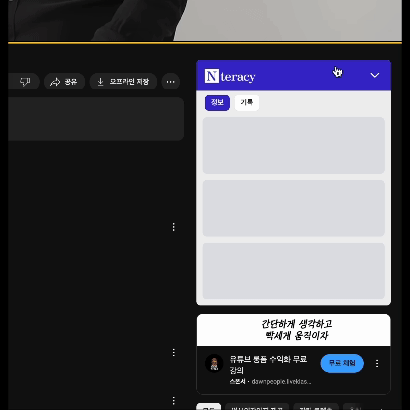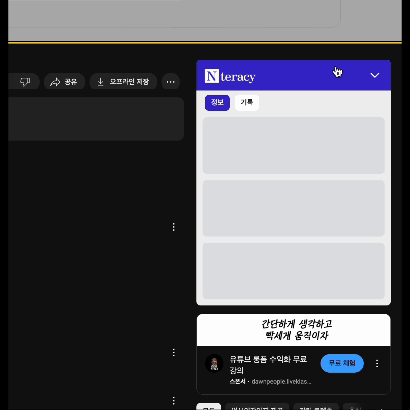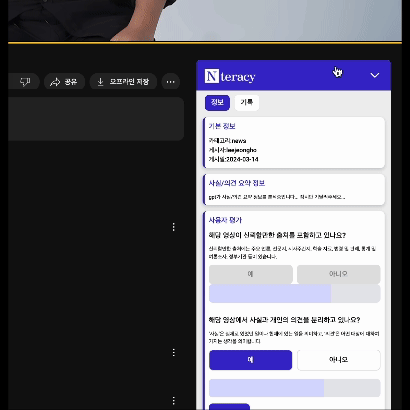
기본 정보 API, 유저 답변 API, GPT API를 병렬적으로 요청하되, 하나의 Suspense로 감싸고 내부에 중첩 Suspense를 적용하는 방법을 적용하였습니다. 그 결과 아래와 같은 결과를 얻을 수 있었습니다.
1. 기본 정보와 유저 답변의 경우 상대적으로 빠르게 오기 때문에 먼저 Skeleton UI를 보여주고 기본 정보와 유저 답변을 화면에 보여주도록 했습니다.
2. GPT 응답은 상대적으로 느리기 때문에 별도의 로딩 화면을 처리하여 기본 정보와 유저 답변을 먼저 사용자에게 제공하고 GPT 응답이 오면 별도로 보여주도록 했습니다.
3. 사용자는 GPT의 응답을 기다리면서 기본 정보와 유저 답변을 먼저 확인하고 서비스의 일부를 사용할 수 있도록 했습니다.
이러한 구조를 통해 UX 측면에서 개선 효과를 얻을 수 있었으며, GPT의 느린 응답 속도의 문제를 자연스럽게 처리할 수 있었습니다.
<Suspense
fallback={Array.from({ length: 3 }, (_, idx) => (
<Skeleton key={idx} className="h-44" />
))}
>
<YoutubeInfoContainer />
<Suspense fallback={<Loading />}>
<GptAnswerContainer />
</Suspense>
<NewsEvaluationForm />
</Suspense>;
5. Remind
이번 계기를 통해 Suspense의 동작 과정을 깊이 이해할 수 있었고 모든 컴포넌트 주위에 Suspense를 두는 것이 최선의 방법은 아니다 라는 점을 깨닫게 되었습니다. 프론트엔드 개발자로서 실제 유저의 입장에서 어떤 로딩 화면을 기대할지 고민하면서 UX에 대한 중요성을 다시 한번 실감할 수 있었습니다. 이를 통해, 보다 직관적이고 효율적인 로딩 처리를 위한 방법을 고민하고 유저에게 더 나은 경험을 제공하는 방향으로 개선할 수 있었습니다.